File
📌file
- 리눅스에서 file은 , 여러 바이트의 시퀀스이다.
- "모든 것이 파일이다"
- 모든 I/O device는 파일로 표현될 수 있다.
- /dev/sda2 -> /usr Disk Partition
- /dec/tty -> 터미널
- 디렉토리도 파일이다.
- 커널도 파일이다
- /boot/vmlinuz-3.13.0-55-generic ~> 커널 이미지
- /proc ~> OS 커널의 자료구조
- 당연히, 프로그램도 파일이다.
- /bin/ls : ls 프로그램
- 각 device와 데이터를 파일화 하는 이유는 커널이 이를 뽑아낼 수 있게 하기 위함이다.
- 즉, 모든 입출력 데이터를 파일화한다.
- 파일 관련 기본 unix i/o(system call)
- open() : 파일 열기
- close() : 파일 닫기
- read() : 파일 읽기
- write() : 파일 쓰기
- lseek() : current file position 을 찾는다.
- 즉, 입출력을 위한 파일 내의 Offset을 찾는다.
- lseek을 통해 파일 Offset을 마음대로 변경할 수 있다.

📌파일 타입
- 각 파일에는 해당 파일이 system에서 가지는 역할에 대한 type이 있다.
- 일반 파일 : 임의의 정보를 가진 일반적인 파일을 의미 (document, audio, program 파일등)
- 디렉토리 : 관련된 파일의 집합을 위한 인덱스를 가지는 파일을 의미 즉, 폴더를 의미
- a.txt , b.txt , c.txt라는 파일들이 workspace라는 디렉토리에 들어있다고 해보자
- 디렉토리도 파일이다. 이 파일에는 다른 파일을 가리키기 위한 인덱스인 innode가 있다.
- 즉, 일반적인 파일 처럼 어떠한 컨텐츠를 가진 것은 아니지만, 내부의 각 파일들을 인덱싱 할 수 있는 table을 가지고 있는 파일을 디렉토리라 하는것
- 소켓 : 다른 머신에 있는 프로세스와 소통하기 위한 파일이다.
- 즉, 이더넷과 같은 네트워크에서 , 프로세스 1이 클라이언트에, 프로세스 2가 서버에 있다면, p1이랑 p2가 서로 소통하기 위해 필요한 파일을 소켓이라 부르는 것이다.

📌file 열기 & 닫기
💡파일을 연다는 것은, 커널에게 " 나 이제 이 파일 접근할 준비됐어 " 라고 알리는 것과 같다.
int fd; /* file descriptor */
if ((fd = open("/etc/hosts", O_RDONLY)) < 0) {
perror("open");
exit(1);
}#include <sys/type.h>
#include <sys/stat.h>
#include <fcntl.h>
int open(char *filename, int flags, mode_t mode);- open 함수를 사용하면, 커널이 리턴 값으로 fd를 반환한다.
- return 값이 -1 이면 에러상황이다.
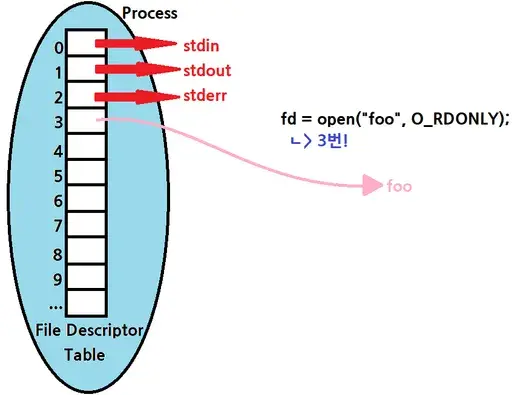
- 프로세스는 file descriptor table을 가진다.
- 리눅스에서 생성된 각 프로세스는 아래의 세 파일 지정자를 default로 가진다.
- 0번 : Standard Input (stdin, STDIN_FILENO)
- 1번 : Standard Output (stdout, STDOUT_FILENO)
- 2번 : Standard Error (stderr, STDERR_FILENO)
- 이 세 파일 지정자는 예약(Reserved)되어 있다. 따라서, 프로세스에서 open함수를 처음 호출하면, 3번 인덱스부터 반환한다.
💡파일을 닫는다는 것은 커널에게 "나 이제 이 파일 접근 끝낼게 " 라고 알리는 것과 같다.
int fd;
int ret; /* Return Value */
// 리턴값을 확인하는 습관은 매우 좋은 습관이다.
if ((ret = close(fd)) < 0) {
perror("File Close Error");
exit(1);
}#include <unistd.h>
int close(int fd);- 마지막으로, 프로세스는 오픈한 파일을 close 함수를 호출해서 닫는다.
📌파일 읽기와 쓰기
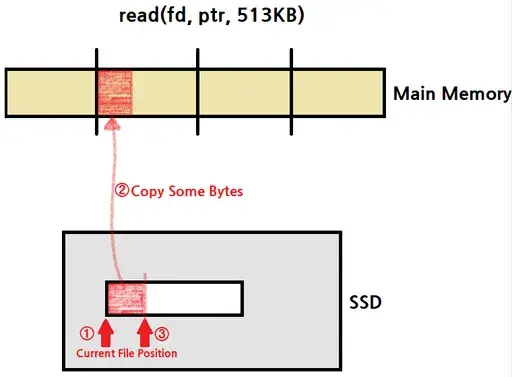
💡파일을 읽는 다는것은 current file position에서부터 복수의 바이트를 복사해서 메인 메모리에 놓고, 그 다음 current file position을 업데이트 하는것이다. 즉, 선 copy 후 fd update이다.
- fd가 어딘가를 가리키고 있고, 그곳에서부터 데이터를 얼마만큼 복사하고, 그러고나서 fd를 옮기고 이런 과정이다.
char buf[512];
int fd;
int m; /* 읽은 바이트 개수 */
if ((fd = open("/etc/hosts", O_RDONLY)) < 0) {
perror("File Open Error");
exit(1);
}
if ((m = read(fd, buf, sizeof(buf))) < 0) {
perror("File Read Error");
exit(1);
}- read(fd, buf , sizeof(buf)의 의미
- fd의 current file position 부터 sizeof(buf)만큼 읽어서 buf에 넣고, 읽은 바이트 개수를 반환한다.
- read 함수의 반환값이 0보다 작으면 에러 상황이다.
- 내가 요청한 사이즈보다 실제 읽은 바이트 수가 적은 것은 에러가 아니다.
- 이를 short count 라고 한다. 위 예시 코드에서 m<sizeof(buf)상황이다.
💡파일에 쓴다는 것은, 메인메모리에서 복수의 바이트를 복사해서 current file position에서 부터 덮어쓰고, 그 다음 current file position을 업데이트 하는 것이다. 즉, 선 복사 후 fd 업데이트 하는것
char buf[512];
int fd;
int m; /* 쓰여진 바이트 개수 */
if ((fd = open("/etc/hosts", O_RDONLY)) < 0) {
perror("File Open Error");
exit(1);
}
if ((m = write(fd, buf, sizeof(buf)) < 0) {
perror("File Write Error");
exit(1);
}- wirte(fd, buf, sizeof(buf))의 의미
- sizeof(buf)만큼 buf를 복사해서 fd의 current file position에서 부터 넣고, 쓴 바이트 개수를 반환한다.
- write 함수의 반환값이 0보다 작으면 에러 상황이다.
- 내가 요청한 사이즈보다 실제 읽은 바이트 수가 적은 것은 에러가 아니다.
- 이를 short count라고 한다. 위 예시코드 m<sizeof(buf) 상황
✏️간단한 c코드
int main(void) {
char c;
while(Read(STDIN_FILENO, &c, 1) != 0) // Wrapper로 씌운 Read/Write
Write(STDOUT_FILENO, &c, 1);
return 0;
}- 터미널에서 문자열이 입력되면, 한문자씩 읽어서 화면에 쓰는 프로그램이다.
- 매우 비효율적인 프로그램이다.
- read와 write는 system call 이다. 즉 overhead가 많다. 한 번의 호출에 대략 20ms정도에 overhead가 난다고 한다. 이는 사람한테 짧은 시간일지 몰라도, 컴퓨터에겐 너무나 긴 시간이다. 위 코드처럼 read/write를 잦게 호출하는 경우, 시간 비효율이 매우 높은 것이다.
read나 write 시에는, 시간 효율을 높이기 위해, 큰 바이트 단위로 읽는 것이 좋다. 일반적으로 Chunk(0.5KB, 512B)단위로 읽고 쓰곤 한다.
RIO Package
📌RIO Package
- roboust for i/o
- 네트워크 입출력에 맞게 알맞게 구현

- RIO Package는 Unbuffered와 Buffered를 모두 제공한다.
- Unbuffered : rio_readn, rio_writen
- Buffered : rio_readlineb, rio_readnb
📌버퍼없는 rio 입력 및 출력 함수
- unbuffered의 경우, unix의 read & write와 동일하다.
- unix의 read & write는 unbuffered input, output 이다
- 네트워크 소켓에서 데이터를 주고받을 때 좋은 성능을 보인다고 한다.
ssize_t rio_readn(int fd, void *usrbuf, size_t n);
ssize_t rio_writen(int fd, void *usrbuf, size_t n);
/* Return */
// num of bytes transferred if OK
// 0 on EOF (rio_readn only)
// -1 on error
- rio_readn은 EOF를 만날때만 short count 상황이 만들어진다.
- 버퍼가 제공되지 않기 때문에 얼마를 읽을지 알고 있을때만 써야한다.
- rio_writen은 short count 상황이 만들어지지 않는다.
ssize_t rio_readn(int fd, void *usrbuf, size_t n) {
size_t nleft = n; // 남은 바이트 수를 저장할 변수 nleft를 n으로 초기화
ssize_t nread; // read 함수의 반환값을 저장할 변수 nread
char *bufp = usrbuf; // 버퍼 포인터를 사용자가 제공한 usrbuf로 설정
while (nleft > 0) {
if ((nread = read(fd, bufp, nleft)) < 0) { // 파일로부터 nleft만큼 읽음
if (errno == EINTR) // 만약 인터럽트가 발생하면 다시 시도
nread = 0;
else
return -1; // 그 외의 오류 상황 시 -1 반환하여 종료
}
else if (nread == 0) // 만약 파일의 끝을 만났을 때
break; // 루프를 종료하고 반환
nleft -= nread; // 읽은 바이트 수를 nleft에서 빼줌
bufp += nread; // 버퍼 포인터를 읽은 만큼 우측으로 이동
}
return (n - nleft); // 읽은 총 바이트 수를 반환
}
📌RIO버퍼를 통한 입력함수
- buffered의 경우 내부 메모리 버퍼를 두어 조금 더 효율적인 입출력을 할 수 있다.
- Unix I/O는 Unbuffered이다. 따라서 Buffered RIO가 더 수행속도가 빠르다.
void rio_readinitb(rio_t *rp, int fd);
ssize_t rio_readlineb(rio_t *rp, void *usrbuf, size_t maxlen);
ssize_t rio_readnb(rio_t *rp, void *usrbuf, size_t n);
/* Return */
// num of bytes read if OK
// 0 on EOF
// -1 on error- rio_readlineb : fd에서 텍스트 라인을 읽을 수 있는대로 최대로 읽고, 버퍼에 넣어 놓는다.
- 네트워크 소켓에서 텍스트를 읽을 때 상당히 효율적이다.
- 종료조건
- MaxLen만큼 바이트가 읽혔을때
- EOF를 만났을 때
- Newline Character를 만났을 때 (이것이 readnb와의 차이)
- rio_readnb : fd에서 최대 바이트만큼 읽을 수 있는대로 읽고, 버퍼에 넣어 놓는다.
- 종료조건
- MaxLen만큼 바이트가 읽혔을때
- EOF를 만났을 때
- 종료조건
📌rio_t 구조체
typedef struct {
int rio_fd; /* 내부 버퍼를 위한 파일 지시자 */
int rio_cnt; /* 내부 버퍼엔 들어있지만 아직 사용자가 읽지 않은 양 */
char *rio_bufptr; /* 내부 버퍼엔 들어있지만 아직 사용자가 읽지 않은 구간의 시작 */
char rio_buf[RIO_BUFSIZE]; /* 내부 버퍼 */
} rio_t;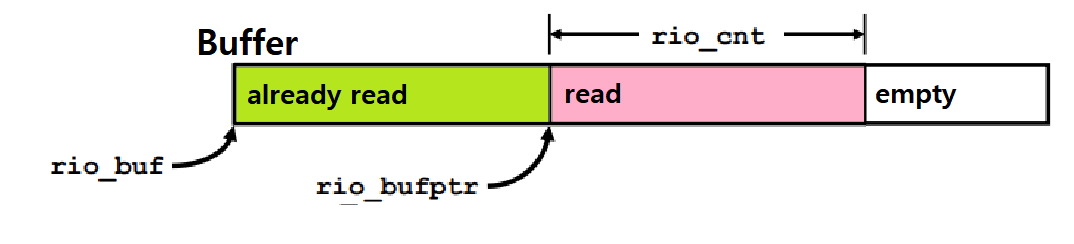
- 이러한 구조체 자료형을 가지고, 그림과 같은 원리로 buffered I/O를 구현한다.
'SWjungle > #컴퓨터시스템' 카테고리의 다른 글
| 메모리 정렬과 패딩 (2) | 2023.09.09 |
|---|---|
| [컴퓨터 시스템 - 7장] 링커 (0) | 2023.09.07 |
| [컴퓨터 시스템 - 3장] 프로시저 / 배열의 할당과 접근 (5) | 2023.09.06 |