데이터의 형식
📌어셈블리 자료형
파이썬과 같은 매우 고급진 언어에서는 list, map, string 등과 같은 편리한 자료형들이 있다. C는 정수, 실수 자료형만 있고, 그 외 struct, array와 같은 기초적인 자료형들이 있다.
그렇다면, 어셈블리어는 어떨까 ? 어셈블리어는 오직 정수, 실수 자료형만 존재하며 array가 없다. 물론 명시된 array가 없을뿐, c와 array 표현방식이 같다. 왜냐하면 연속하는 메모리 공간을 사용하면 array라고 생각할 수 있기 때문이다.
- 어셈블리 정수 자료형은 1,2,4,8byte 짜리가 존재
- 실수 자료형은 IEEE 754(부동소수점 표현)에 맞춰 4, 8, 10byte가 존재
- 포인터는 전부 정수자료형으로 표현된다. 즉 정수 자료형은 값을 의미할 수도, 주소를 의미할 수도 있다.
💡word
- 기계는 4바이트, 8바이트식으로 단위를 세지 않고 word라는 단위를 사용한다.
- 이를 기본으로 16비트 데이터 타입을 워드, 32비트는 더블워드, 64비트는 쿼드 워드로 부른다.
- 8,16,32,64비트를 어셈블리어 접미사로 각각 b, w, l, q로 표현한다.
- word는 기계가 한 번의 명령에 처리할 수 있는 자료의 수를 나타내는데, x86-64에서는 16비트, 즉 2바이트이다.
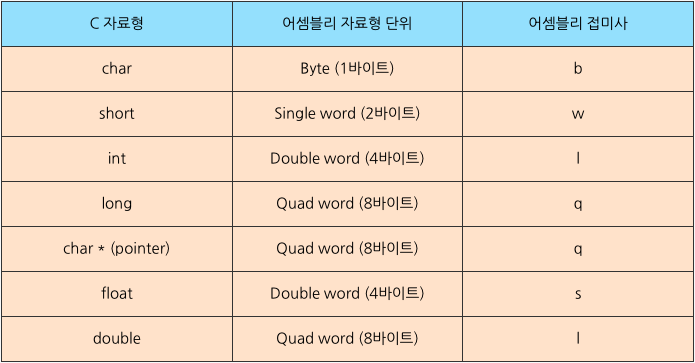
- 어셈블리는 word의 크기를 단위로 삼아 이동할 자료의 양을 결정한다.
- 위의 예시에서 볼 수 있는 어셈블리를 보면 다음과 같은 명령어를 볼 수 있다.
movp %rdx, %rbx // mov+q ; mov 명령어와 접미사 q의 조합
retp // ret+q ; ret 명령어와 접미사 q의 조합- movq 와 retq에 주목하자. 이 둘은 각각 mov, ret 명령어에 접미사 q가 붙은 형태이다.
- 접미사는 처리할 자료의 양에 따라 정해진다. c 자료형과 비교해서 보면 좋다.
- 위 표에 따르면 다음과 같이 생각할 수 있다.
- -short 자료형을 처리하는 mov 명령어는 movw( mov + w(word) ; ) 이다.
- -int 자료형을 처리하는 add 명령어는 addl ( add + l (double word) ; ) 이다.
- -long 자료형을 처리하는 lea 명령어는 leaq ( lea + q (quard) ; ) 이다.
📌레지스터
- 어셈블리는 cpu 작업에 매우 친화적인 언어이기 때문에 기계의 특성을 100% 반영한다.
- cpu는 레지스터에 값을 담아두고 계산을 하고, 메모리에서 값을 가져온다.
- 계산할 수 있는 대상은 레지스터가 전부이기 때문에 무조건 레지스터를 이용한 계산을 하게 된다.
- 이 떄문에 레지스터를 이용한 계산을 하는 명령어가 대부분으로 구성되어 있다.
- 또한 조건 코드가 존재하기에 조건 코드 설정 및 이용하는 명령어도 어셈블리에 들어있다.
👉🏻x86-64 CPU의 16개의 정수형 레지스터

- 우선 파란 사각형은 8바이트의 정수를 담을 수 있는 레지스터이다. (%rax, %rbx, %rcx, ......)
- 파란 사각형 안에 있는 주홍색 사각형들은 4바이트의 정수를 담을 수 있는 레지스터이다.(%eax, %ebx, ....)
- 8바이트 레지스터와 4바이트 레지스터는 분리되어 있는 것이 아니다.
- 위의 그림을 보면 %rax 안에 %eax가 들어있는 것이다.
- 즉, %eax는 %rax와 위치가 같지만 레지스터를 단 4바이트만 사용하는 것이다.
- 어셈블리에서 %rax 대신 %eax를 사용한다면 4바이트만 필요한 경우라고 생각할 수 있다.
- 가장 특이한 레지스터는 %rsp(스택포인터)로, 스택의 끝 부분을 가리킬 때 사용된다.
- 나머지 15개의 레지스터는 비교적 사용이 자유롭지만, programing convention이 존재한다.
Callee saved register - callee가 해당 레지스터 값을 변경하지 않는 것을 보장하는 레지스터. caller는 해당 레지스터 값이 변경되지 않음을 예상할 수 있다.
Caller saved register - callee는 해당 레지스터를 변경할 수 있다. 그러므로, caller는 해당 레지스터 값을 저장해 두었다가 회복(restore)시켜야 할 것이다.
※programing convention : 코드를 작성할 때 일정한 규칙과 규약을 따르는 것을 의미
프로시저
📌프로시저
- 프로시저는 지정된 인자들과 리턴 값으로 특정 기능을 구현하는 코드르 감싸주는 방법을 제공한다.
✏️예)프로시저 P가 프로시저 Q를 호출한뒤, Q가 실행된 후 다시 P로 리턴한다고 가정
P(){
Q();
}-이러한 동작들은 다음과 같은 하나 이상의 메커니즘과 연관됨
- 제어권 전달 : 프로그램 카운터(PC)는 Q에 진입할 때, Q에 대한 코드의 시작주소로 설정됩니다. 리턴하는 경우 P에서 Q를 호출한 후 진행되어야 할 다음 인스트럭션으로 설정되어야 한다.
※프로그램 카운터 : CPU 내부에 있는 레지스터 중 하나로, 현재 실행 중인 프로그램의 다음 명령어의 위치를 가리키는 역할을 한다.
※인스트럭션 : 컴퓨터가 수행해야 할 작업을 명시적으로 정의하는데 사용
- 데이터 전달 : P는 하나 이상의 매개변수를 Q에 제공할 수 있어야 하며, Q는 다시 P로 하나의 값을 리턴할 수 있어야 한다.
- 메모리 할당과 반납 : Q는 시작할 때 지역변수들을 위한 공간을 할당할 수도 있고, 리턴할때 이 저장소를 반납할 수 있다.
📌런타임 스택
- c언어를 포함한 대부분의 언어에서 프로시저 호출 동작 방식의 주요 특징은 스택 구조가 제공하는 후입선출 메모리 관리 방식을 활용할 수 있다는 점이다.
- Q가 실행되는 동안에는 자신의 지역 변수를 위한 새로운 저장공간을 할당할 수 있는 능력이나 다른 프로시저로의 호출 설정하는 능력만을 필요로한다. 반대로 Q가 리턴할 때는 자신이 할당받은 로컬 저장장소로 반납될 수 있다.
- 따라서 프로그램은 스택을 사용해서 프로시저들이 요구하는 저장장소를 관리 할 수 있으며, 여기서 스택과 프로그램 레지스터들은 제어와 데이터를 전송하기 위해, 그리고 메모리를 할당하기 위해 필요한 정보를 저장한다.
💡스택의 구조
- x86-64의 스택은 작은 주소 방향으로 성장하며, 스택 포인터 %rsp는 스택의 최상위 원소를 가리킨다.
- 데이터는 pushq와 popq 인스트럭션을 이용해서 스택에 저장되고 읽어올 수 있다.
- 특정 값으로 초기화 되지 않은 데이터를 위한 공간은 , 스택 포인터를 적당히 감소시키는 것을 통해 할당할 수 있다.
- 유사하게 할당받은 공간은 스택 포인터를 단순히 증가시키는 것만으로도 반납할 수 있다.

- x86-64 프로시저가 레지스터들에게 저장할 수 있는 개수 이상의 저장 공간을 필요로 할때는 공간을 스택에 할당한다.
- 이 영역을 해당 프로시저의 스택 프레임 이라고 부른다.
- 현재 프로시저에 대한 프레임은 항상 스택의 맨 위에 위치한다.( = top, 가장 낮은 주소, 낮은 방향으로 성장하므로)
👉🏻예) 스택 프레임의 동작 방식
int main()
{
func1() // func1() 호출
return 0;
}
void func1()
{
func2() // func2()호출
}
void func2()
{
}- 다음 그림은 코드에서 함수 호출에 의한 스택 프레임의 변화를 보여준다.


출처 : -TCPSCHOOL.com
- 프로그램이 실행되면, 가장먼저 main() 함수가 호출되어 main() 함수의 스택 프레임이 스택에 저장된다.
- func1() 함수를 호출하면 해당 함수의 매개변수, 반환 주소값, 지역 변수 등의 스택 프레임이 스택에 저장된다.
- func2() 함수를 호출하면 해당 함수의 스택 프레임이 추가로 스택에 저장된다.
- func2() 함수의 모든 작업이 완료 되어 반환되면, func2() 함수의 스택 프레임만이 스택에서 제거된다.
- func1() 함수의 호출이 종료되면, func1() 함수의 스택 프레임이 스택에서 제거된다.
- main() 함수의 모든 작업이 완료되면, main() 함수의 스택 프레임이 스택에서 제거 되면서 프로그램이 종료된다.
💡STACK 의 pop,push

- 그림을 잘 보면 스택의 bottom 이 위쪽에 있고, top 이 아래쪽에 있다
- stack은 메모리를 더 사용할수록 밑으로 자라난다.
(cf. heap 은 위로 자라남) - rsp 라는 특수한 레지스터가 스택의 맨 아래 주소를 가리키고 있다.
👉🏻스택의 PUSH
pushq src

- 스택에 원소를 push 하면 rsp 가 가지고 있던 주소값을 내려준다 (즉, %rsp 레지스터가 가리키고 있던 주소를 8byte 만큼 뺴준다.)
- 자동으로 rsp 의 주소값을 8을 빼주거나 더한다.
(movq 와 같은 명령어로 데이터를 삽입하는 명령어들은 내가 직접 %rsp 주소값을 직접 빼주거나 더해야함)
👉🏻스택의 POP
popq dst
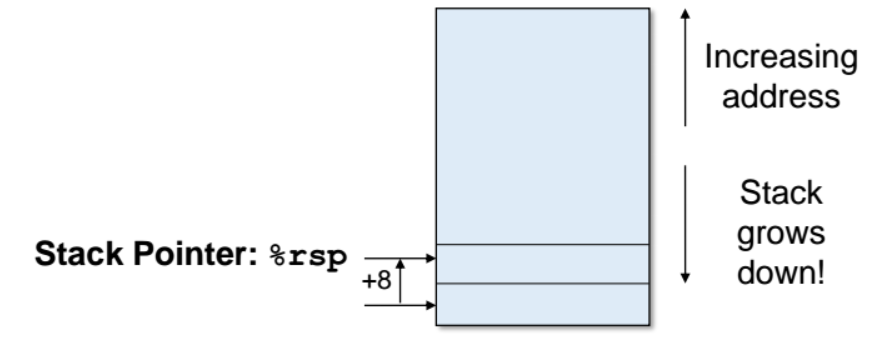
- 8 byte 만큼 더한다.
- dst(destination) 은 반드시 memory 이여야한다.
📌제어의 이동
💡CALL
명령어 : callq jump할주소 < 함수명 >
ex) callq 400544 < func1 > => 함수 func1 을 호출하고 400544 라는 주소로 jump 한다.
- 제어 함수 P에서 Q로 전달하는 것은 단순히 프로그램 카운터를 Q의 시작 인스트럭션으로 설정하는 것과 관련
- 이후 Q가 리턴해야 할 때가 오면 프로세서(cpu)는 P의 실행을 다시 시작해야 하는 코드 위치에 대한 정보를 가지고 와야한다.
- 해당 정보는 x86-64 기계에서는 call Q인스트럭션을 사용하여 Q를 호출하는 동시에 리턴 주소를 기록한다.
- 해당 인스트럭션은 return address A를 스택에 push한 뒤, PC를 Q의 시작 인스트럭션의 주소로 설정합니다.
- 이때, return address는 P에서 call 바로 다음에 존재하는 인스트럭션의 주소로 계산됩니다.
- call 인스트럭션은 호출된 프로시저가 시작하는 인스트럭션의 주소를 목적지로 갖는다. 점프와 유사하게 인스트럭션은 직접 점프 혹은 간접 점프 형태를 가진다.
※ 점프 : 프로그램의 실행 흐름을 변경하는 명령 또는 작업을 가리킨다. 프로그램에서 점프를 사용하면 특정한 조건에 따라 다른 부분의 코드로 이동하거나, 루프를 제어하거나, 서브루틴에서 호출한 위치로 복귀하는 등의 동작을 수행
- 어셈블리 코드에서 직접 점프의 목적지는 레이블로 주어지는 반면에 , 간접 점프의 목적지는 *와 주소지정형식을 통해 설정됨
💡RET
명령어 : ret
- call에 대응하는 인스트럭션 ret은 주소 A를 스택에서 pop한 뒤, pc를 A로 세팅
💡 ret address
- call이 일어날때 함수의 내용을 수행 후 종료될때 다시 자기가 돌아갈 주소를 알고 있어야한다.
✏️call 예제
👉🏻과정1

- 400550 : callq 400500<mult2>
- --> mult2라는 함수호출이 발생하면 400550이라는 주소로 점프한다 (400500 == mult2 함수의 시작 주소)
- rsp = stack의 시작주소
- rip = 현재 수행중인 명령어 코드를 가리키는 레지스터(포인터)이다.
👉🏻과정2

- mult2 함수를 호출 후 종료될때(함수가 return 될때) 다시 돌아올 주소를 스택에 top에 저장한다.(push)
- 스택에 저장된 되돌아갈 주소는 400549
- top에 저장하기 위해선, 기존 스택의 top에 저장되어 있던 데이터를 한칸 미루고 생긴 빈공간에 push 하면 된다.
👉🏻과정3

- rip 레지스터(포인터)가 함수의 return 구문을 가리키고 있다. 함수가 종료되면서, 스택에 저장되어 있었던 주소로 되돌아가면 된다.
👉🏻과정4
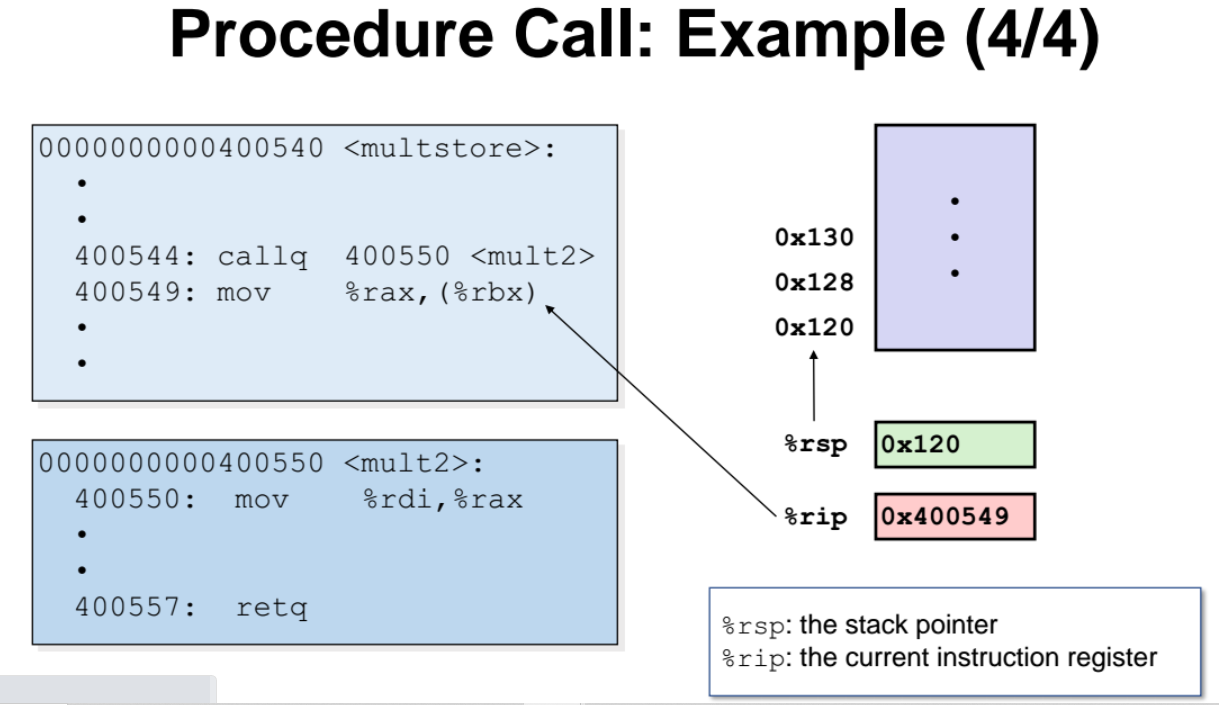
- 400549 주소로 다시 되돌아가고, 스택에 저장되어 있던 주소를 삭제시킨다.
📌데이터 전달

어셈블리에서는 함수의 인자를 register와 stack을 활용해서 제한없이 받을 수 있다.
- register에는 최대 6개 까지 인자 할당이 가능하고, 그 이상 오바되면 스택에 인자들이 쌓인다.
- 함수의 주는 input 값은 rdi, rsi, rdx, rcx, r8, r9 순으로 들어간다.
- 위 그림에 보이는 레지스터 6개만 함수 호출시 input에 넣어줄 수 있다.
- 만일 함수의 인자가 6개가 넘어 가면 스택에 쌓인다.
- 스택의 함수의 7,8,....,n번째 인자가 차례대로 쌓이는데 거꾸로 쌓인다. 스택의 맨 아래가 top이므로
✏️예제)

메모리 할당과 반납
📌지역 데이터 관리
- 함수 호출이 가능한 언어들 ( stack 활용)
- -> 현재 수행하고 있었던 프로그램들이 한줄한줄 내려가다가 다른곳으로 점프하고 다시 되돌아 오는 것이 가능한 언어들
- 새로운 함수를 호출할 때 return address를 스택에 저장해 놓고 stack pointer(%rsp)를 최신화 하는데 이전의 함수에 대한 데이터들을 보지 않고 나만의 데이터를 새롭게 관리하겠다는 개념
- 즉, 현재 호출된 함수에 대해서만 신경쓰고 관리
📌call chain

- yoo() 함수가 who()를 호출하고, who() 함수가 ami() 함수를 호출하고, ami 함수는 재귀함수로써 자기 자신을 호출한다.
- 이렇게 함수가 불리고 불리는 관계를 트리 형태로 그려 놓은 것을 call chain 이라고 한다.
📌Stack Frame
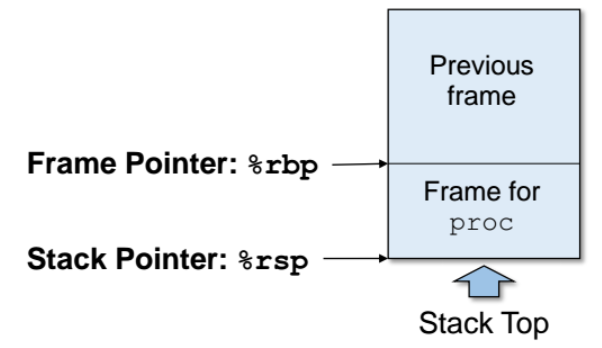
- 각 함수마다 자신만의 stack frame을 가지고 있다.
- 각각의 함수는 자신만의 스택 공간이 있어서, 자신의 스택 공간에만 각자 데이터를 할당 가능하다.
- 예를들어) 함수 안에 int a; 를 선언하면 자신의 스택에 할당한다.
- 함수 호출시 스택에 지역 변수들이 push 되다가 마지막에 return address 가 push된다. 여기까지가 해당 함수의 stack frame이다. 이 과정이 다 끝나면 또 다른 새로운 함수가 호출될 것이다.
- 각 함수에 대한 stack frame 마다 가지고 있는 데이터는 다음과 같다.
- return information
- local storage
- temporary space
- 스택 frame의 할당은 function call을 할때 일어나고, 해제는 함수를 return 할때 실행된다.
📌stack frame 예제
👉🏻과정 1
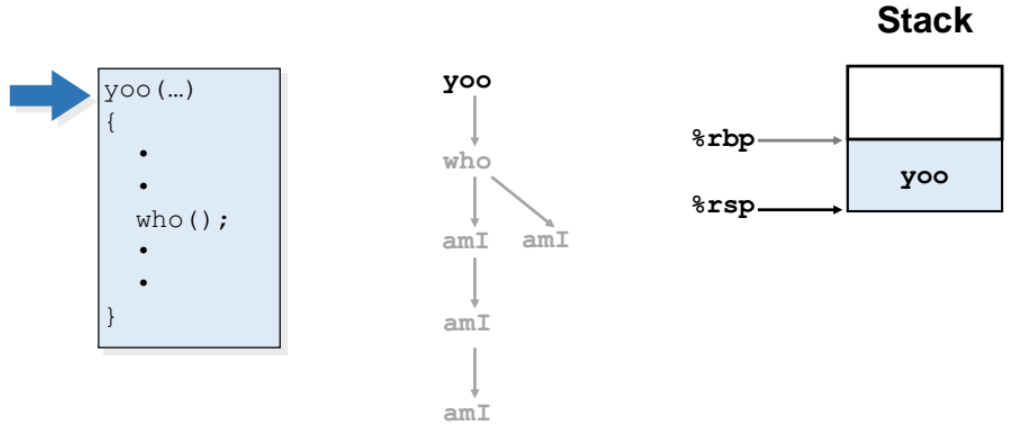
- 위와 같이 call chain이 생겼다. yoo - who - ami - ami 구조이다.
- rsp가 스택의 top을 가리키고, rbp는 stack의 시작점을 가리킨다.
👉🏻과정 2

- 새로운 함수(who)의 stack frame이 생겼다.
👉🏻과정 3
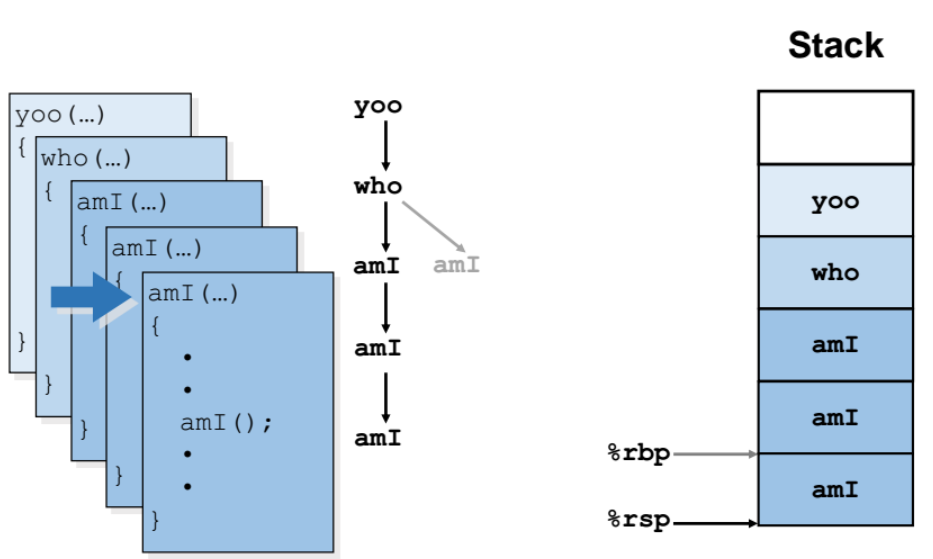
- 재귀함수 ami에 대해서 각각 따로 새로운 stack frame이 생성된다.
👉🏻과정 4

- ami가 return됨
👉🏻과정 5(리턴)
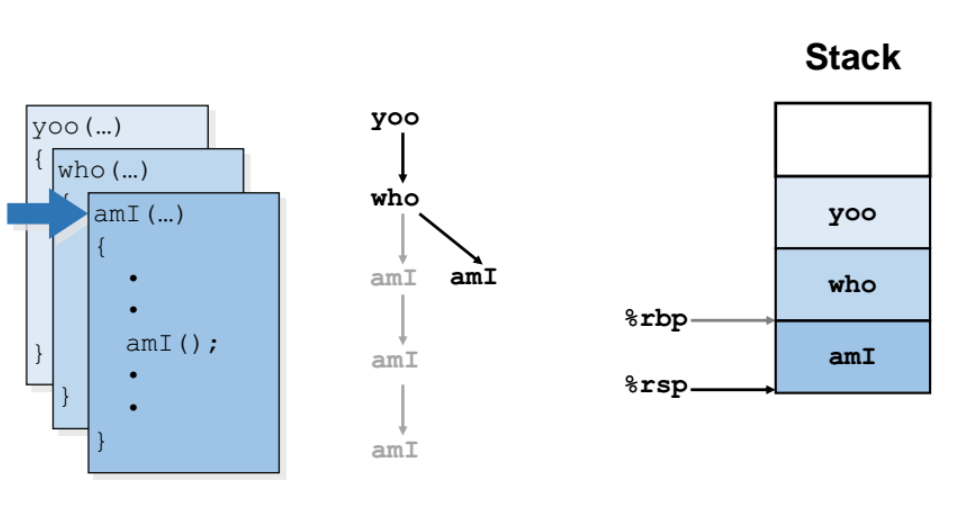
👉🏻과정 6(리턴)

👉🏻과정 7(리턴)
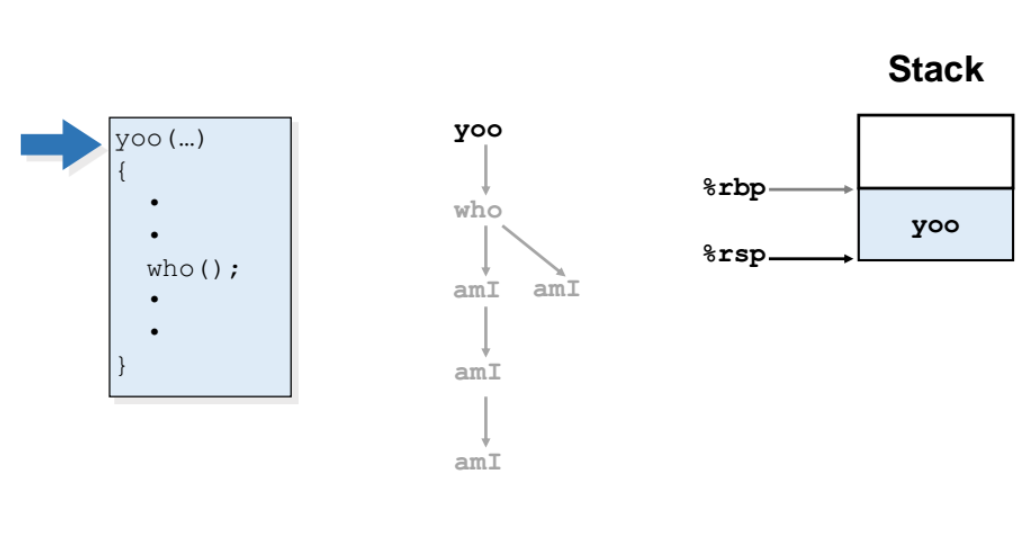
📌재귀

terminal case == base condition
- testq %rdi %rdi : %rdi 값이 0인가 아닌가를 묻는것
(testq a b : a 와 b 를 AND 하는것. 즉, a와 b 둘다 0이면 0이되고, 둘중 하나라도 0이면 0이고, 둘 다 1이여야지만 1이된다.
👉🏻예제)

- rbx에 대해 caller saved가 되었다. 새로운 함수들이 재귀함수로써 계속 호출되어도, 현재 함수에 대한 rbx에는 계속 데이터가 저장되어있어야 함

- calle saved로써 재귀구조에서 직전에 자신을 불러준 함수의 데이터를 스택에 계속 종료되기 전까지 저장한다. 변하지 않는 값
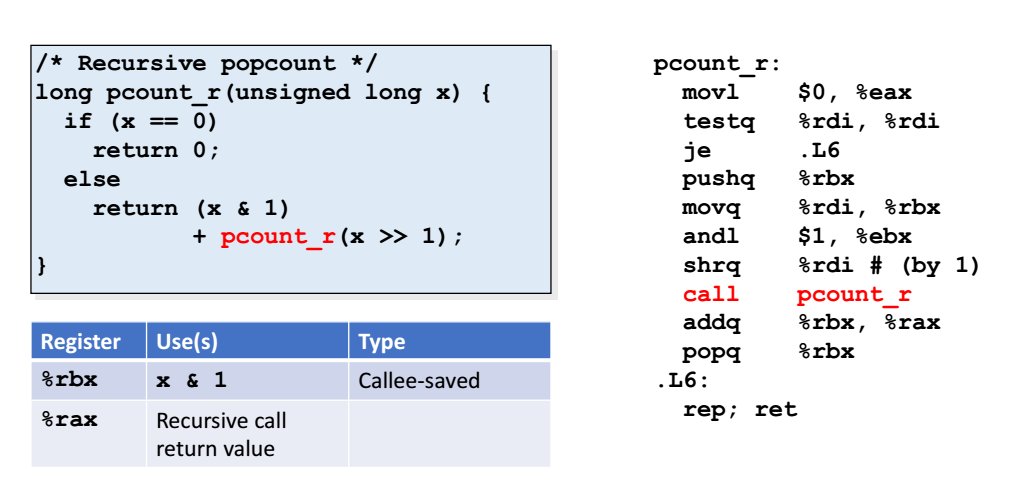
- (x & 1) 과 pcount_r(x >> 1) 을 더해서 리턴해줘야하는데, 아직 재귀함수가 돌지 않아서 pcount_r(x >> 1) 의 값을 모른다.
- movq %rdi, %rbx : 따라서 rbi ( = x) 의 값을 rbx 에 저장해두고, andl $1, %ebx : x에 AND 연산, 즉 x & 1 을 하고 다시 rbx (=ebx)에 저장해둔다.
- shrq : 그러고나서 rdi 가 저장하고 있는 값에대해 쉬프트연산을 한 값을 pcount_r 의 인자로 넣어준다.

- 재귀가 끝나고 나면 rbx 쟁겨놨던 값과 함수의 리턴값을 rax 에 넣어서 리턴시킬 준비를 한다.

- 그러고 자신을 불러준 함수에 대한 데이터의 공간인 rbx를 pop해준다.
배열의 할당과 접근
📌배열
- 스택에 쌓임
- 배열이름 : 포인터 ( 배열의 주소를 리턴해줌)
- -> val + i : int 형 배열 시작주소에 i바이트 만큼 더한것

✏️예제)
- rdi == z(배열의 시작주소)
- rsi == digit( 배열의 digit 번째 인덱스 번호)

- movl(%rdi, %rsi, 4), %eax : 배열의 시작 주소인 rdi 에서 digit x 4byte 만큼 이동해서 그곳에 있는 값을 eax에 담아서 리턴
📌다중 배열

- 배열의 크기 : row x colum x 타입크기 (예. int = 4)
- 저장방식 : row-major 구도로 저장
- row - major 한 row 단위씩 이어서 저장하는것, 한 row 단위를 저장 했다면 바로 뒤에 row 단위를 이어서 저장한다.(아래그림)

- column-major : 한 column 단위씩 이어서 저장. ( 아래 그림)

✏️예제)
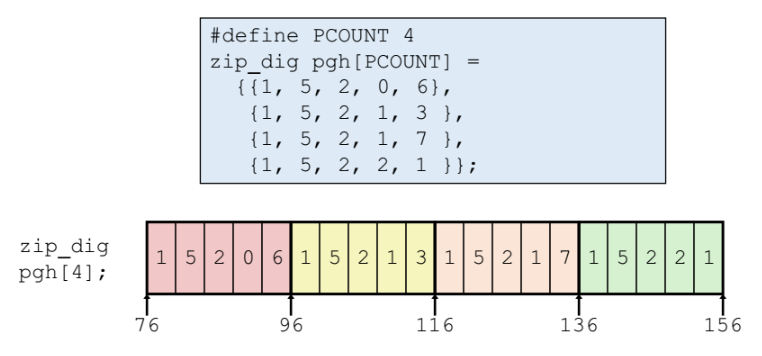
- row 가 한줄 한줄 들어간다.
📌다차원 배열 접근 방식

- i행 j열 원소에 접근하고 싶은경우
👉🏻과정1) row 계산
A + i * ( C * K )
(i : K: 배열타입 크기. int형의 경우 4)- 배열의 시작주소 A에서 시작해서
- C * K 는 row 한줄의 사이즈(크기)이다.
👉🏻과정2)
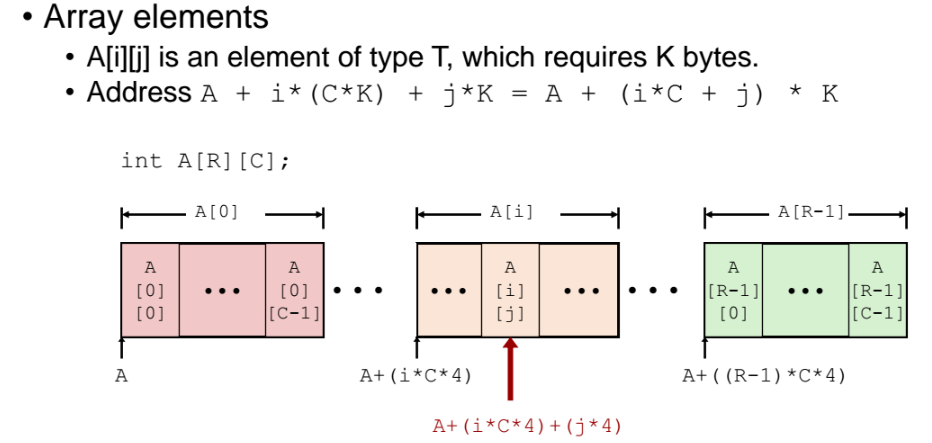
- 앞서 구해낸 row 값 (= A + i x ( C x K)) 에다 j * K 를 하면 끝
👉🏻예제 ) row 구하기

- rdi == 인덱스 번호
- leaqq(%rdi, %rdi, 4), %rax : row 한줄의 크기가 원소 5개로 이루어져있고, 이는 곧 20바이트 크기라는 소리가 된다.
- leaq pgh(, %rax, 4) : pgh 배열의 시작주소에서 20 x rdi, 즉 20 x 인덱스번호 만큼 이동하여 그곳에 있는 값을 rax 에 담아서 리턴
👉🏻예제 ) row + column 구해서 접근

- index == row 값
- dig == column 값
'SWjungle > #컴퓨터시스템' 카테고리의 다른 글
| Unix I/O (1) | 2023.09.17 |
|---|---|
| 메모리 정렬과 패딩 (2) | 2023.09.09 |
| [컴퓨터 시스템 - 7장] 링커 (0) | 2023.09.07 |